[GNU/LINUX Magasine et auteur de cet article, en le remerciant, Tristan Colombo / Sans oublier la source du projet.]
Cet article présente ATOP, un outil en ligne de commandes interactif pour la supervision de performance sur des systèmes basés sur Linux. Nous explorerons ses fonctionnalités en montrant comment il permet d’extraire divers compteurs de performance avec un niveau de détail très fin. Son interface interactive en ligne de commandes étant inadaptée pour être utilisée efficacement dans un contexte de supervision opérationnelle, nous montrerons aussi comment, avec quelques astuces et des scripts spécifiques, les compteurs d’ATOP peuvent être extraits, agrégés et injectés dans Graphite (installation), afin d’être visualisés avec Grafana (installation) dans un environnement opérationnel.


ATOP est un outil de supervision de performance basé sur Linux. Fonctionnant en ligne de commandes à l’instar d’outils comme TOP ou HTOP, plus connu, ATOP fournit divers compteurs et un niveau de détail très fin concernant toutes les ressources critiques d’un système (CPU, mémoire, couches réseaux, disques et processus). Nous aborderons quelques-unes de ses fonctionnalités clés dans cet article. Souffrant malgré tout d’une interface de visualisation de type ncurses, c’est_à_dire en mode texte depuis un terminal, cette interface est très peu adaptée pour une supervision opérationnelle. C’est pour cela que nous nous intéressons aussi dans cet article, à montrer comment les compteurs fournis par ATOP peuvent être extraits, agrégés et visualisés à partir d’outils évolués comme Grafana. En effet, après avoir présenté les fonctionnalités d’ATOP, nous montrerons des astuces et des scripts développés par l’équipe GNU/LINUX Magasine, qui tirent parti des options offertes par ATOP pour permettre d’extraire des compteurs, de les agréger et de les injecter dans une base de données Graphite pour ensuite les visualiser avec Grafana. Ce dernier permettant de créer des tableaux de bord évolués, qui simplifient grandement l’exploration, l’analyse et le partage en temps réel des indicateurs de performances dans un contexte de supervision opérationnelle.
Cet article étant centré sur ATOP, il n’abordera que sommairement Graphite et Grafana en montrant surtout comment ces derniers peuvent être utilisés comme outils de visualisation complémentaires pour ATOP. En particulier, nous ne traiterons pas de l’installation et de la configuration de Graphite et Grafana. Du coup, il est fort possible que je sorte un peu de cet article pour y ajouter ses configurations de ces applications utile à ATOP. On verra car malgré tout, cet article met la lumière sur une fonctionnalité phare de la version 3.1 de Grafana, la dernière à être publiée lorsque cet article été écrit. Cette fonctionnalité permet de partager des modèles de tableaux de bord via un site internet dédié.
ATOP offre diverses caractéristiques fondamentales à plusieurs égards supérieurs à celles offertes par d’autres outils de supervision de performance Linux :
| ► supervision de l’utilisation de toutes les ressources critiques d’un système (CPU, mémoire/swap, disque, réseau, processus).
► historisation permanente de l’utilisation des ressources pour permettre une analyse post-mortem. ► visualisation de la consommation des ressources par tous les processus. ► consommation de ressources par processus (lourd ou léger), pris individuellement. ►collecte pour chaque processus, lourd ou léger, des compteurs concernant : le CPU, la mémoire, la swap, les disques (volumes LVM inclus), la priorité, l’utilisateur, l’état, et le code de sortie. ► filtre selon l’état des processus (actifs et inactifs). ► mise en évidence des écarts de consommation dans le temps. ► cumul du temps d’activité des processus en fonction de l’utilisateur. ► cumul du temps d’activité des processus en fonction du programme exécuté. ► activité réseau en fonction des processus. ► fonctionnement en mode interactif et en mode non-interactif avec l’option d’extraction de données. |
01 ) PREMIER PAS AVEC ATOP .
01.1 – Installation :
L’installation d’ATOP est simple, à partir des sources ou à partir des paquets RPM disponible en téléchargement sur le site du logiciel. Depuis la version 2.2, vous pouvez avoir des paquets spécifiques pour des systèmes basés sur systemd, en plus des paquets System V historiquement fournis.
Voici la commande pour l’installer depuis un paquet RPM depuis le site :
~$ rpm –ivh http://www.atoptool.nl/download/atop-2.2-3.sysv.x86_64.rpm
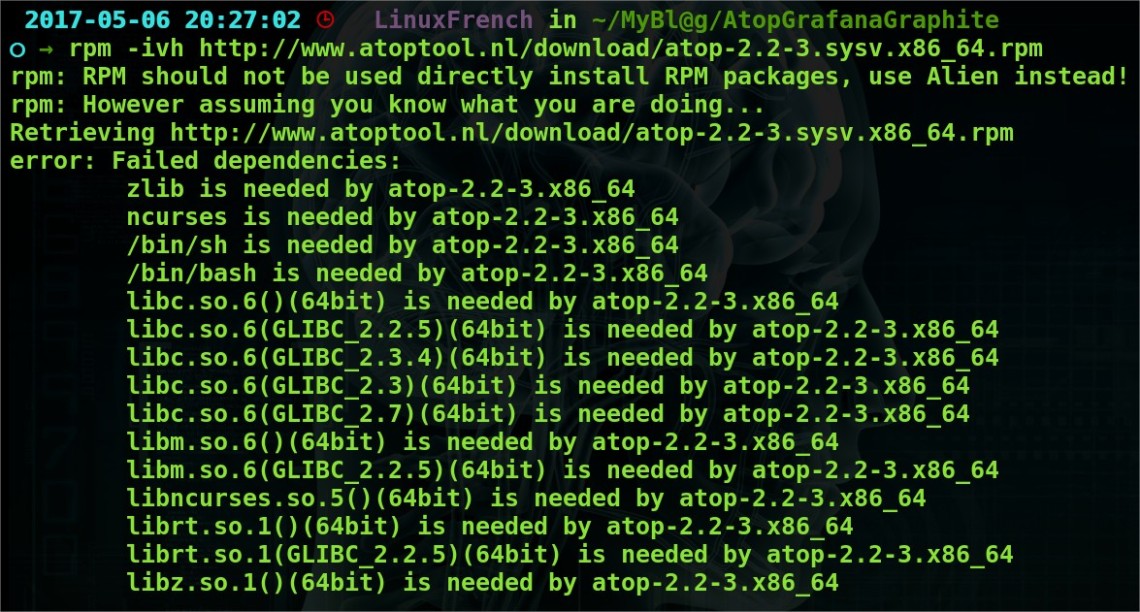
(comme vous pouvez le remarquer, après le lancement de la commande « rpm« , celui nous conseil (et j’en fait autant), d’installer l’utilitaire « alien » qui permet d’installer n’importe quel paquet « .rpm » ou « .deb » tout en le configurant par la même occasion. Ensuite, on peut remarquer que la sortie de la commande me retourne des erreurs dût à des dépendances manquantes. De ce fait, par facilité, je vais pas aller chercher toutes ses ses dépendances manquantes mais je vais utiliser l’outil « aptitude » pour voir si le paquet est disponible et si c’est le cas, l’installer par se biais.)
Voyons ça :
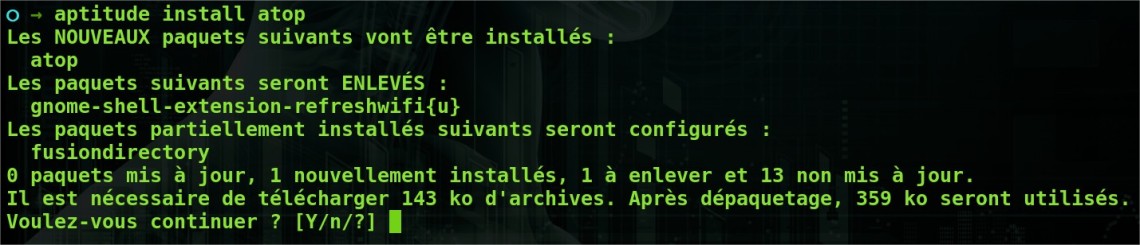
~# aptitude search atop

(super ! le paquet est présent.)
~# aptitude install atop
01.2 – Démarrer ATOP :
Une fois installé, le programme se lance avec la commande suivante :
~$ atop

Ceci démarra l’interface interactive basée sur ncurses que nous décrirons après.
01.3 – Comprendre les compteurs de performance d’ATOP :
L’interface d’ATOP se compose de deux parties :
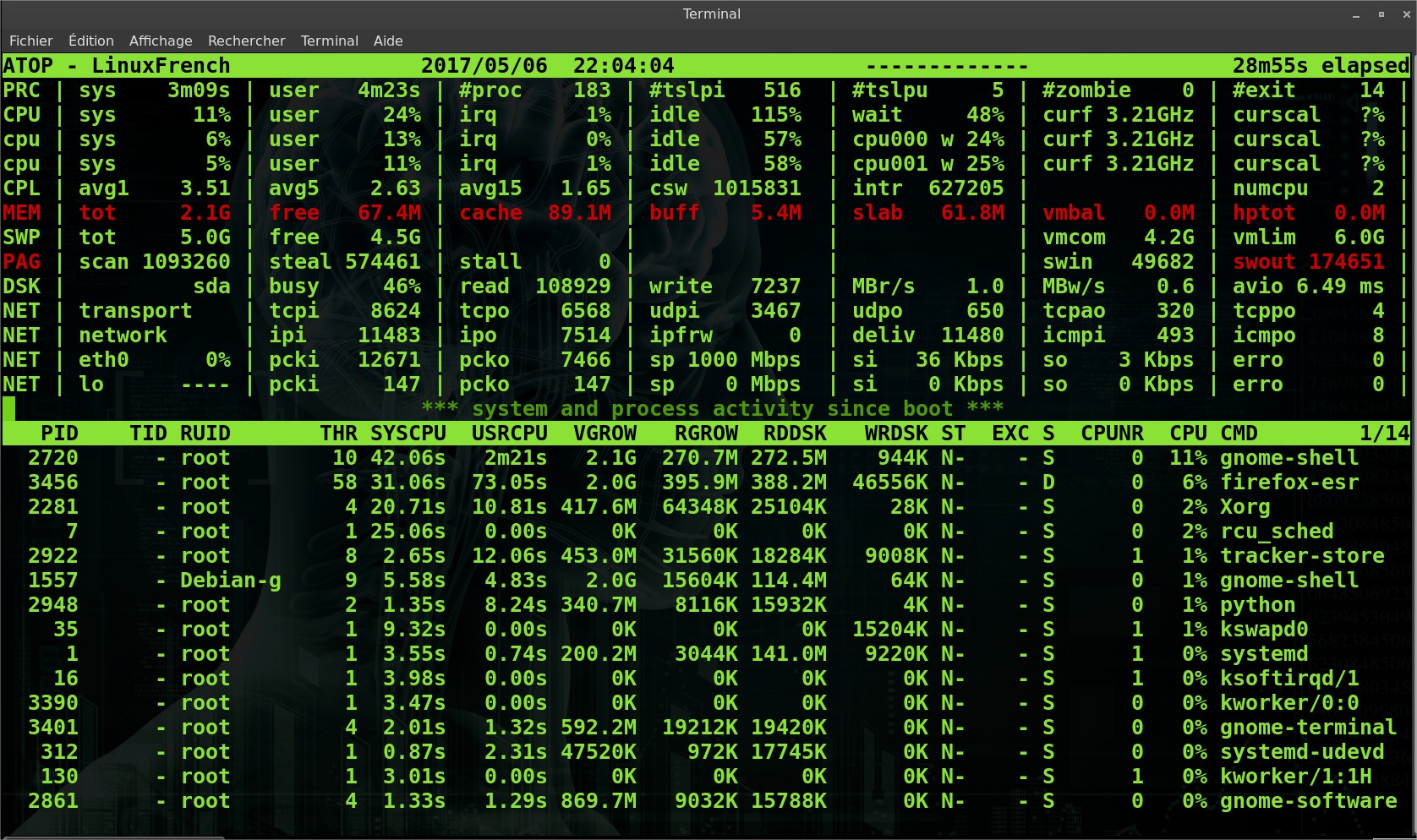
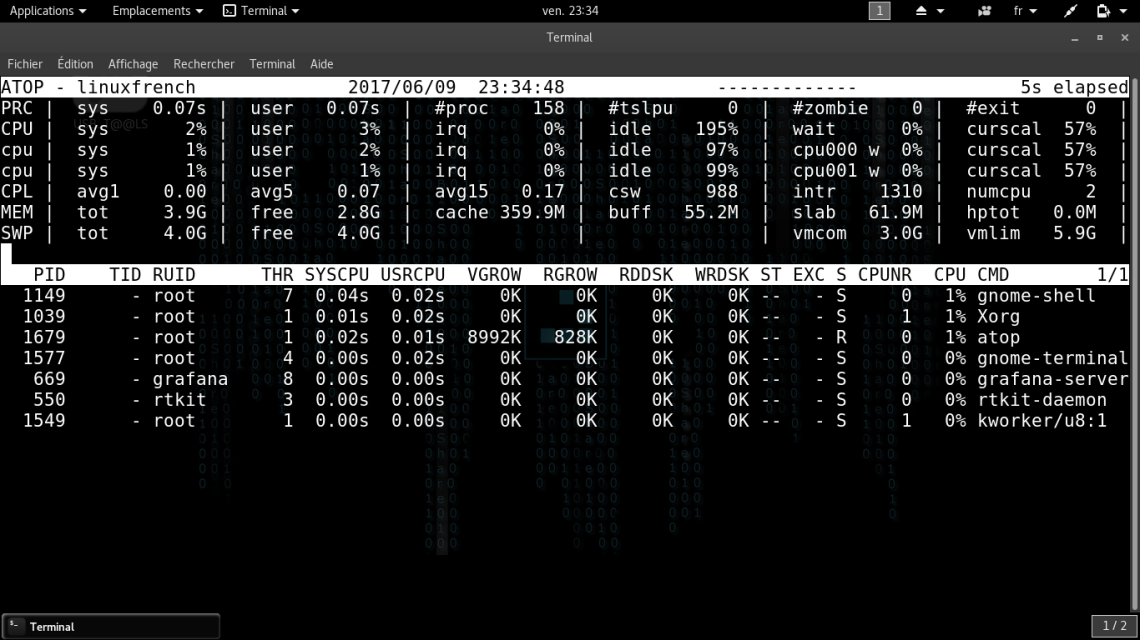
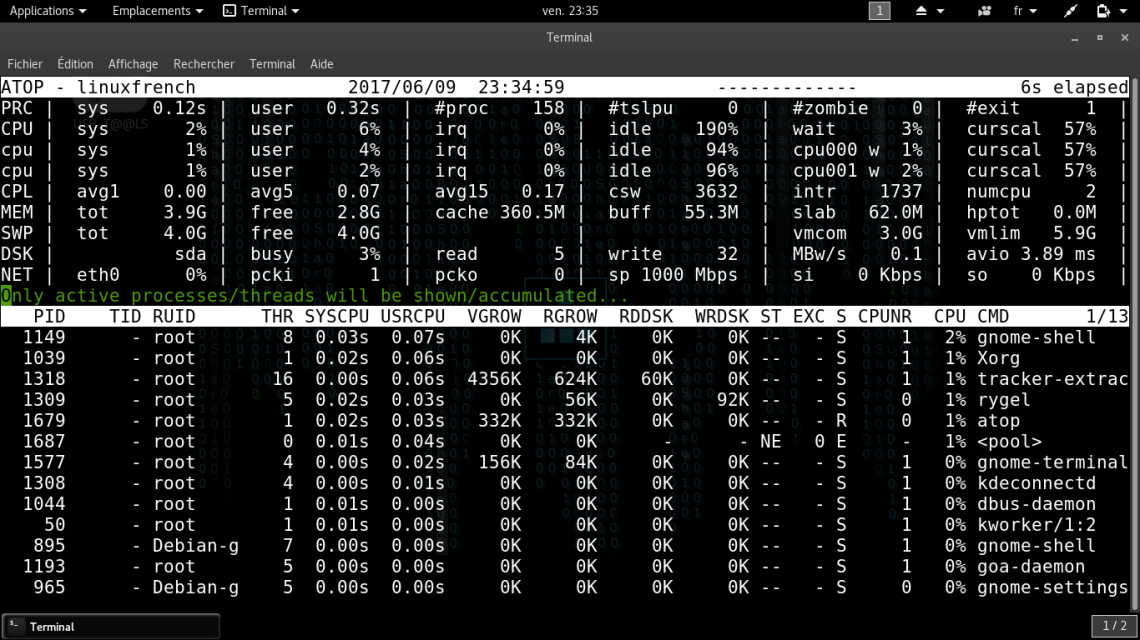
| ► Les statistiques système, dans la partie supérieure délimitée par la bande blanche (voir capture d’écran ci-dessous), présentant des compteurs globaux d’utilisation des ressources. Par défaut ces compteurs concernent les ressources suivantes : CPU, mémoire, swap et disques. Selon des options de ligne de commandes ou des requêtes soumises depuis l’interface interactive, les compteurs liés aux ressources peuvent être affichés (swap, ordonnanceur, et bien d’autres encore). Nous y reviendrons dans la suite de cet article. Selon le niveau d’utilisation d’une ressource donnée, les compteurs associés peuvent être affichés avec une couleur spécifique afin de mettre en évidence son niveau de saturation. Sur l’image ci-dessous, on peut par exemple observer que les compteurs liés au premier CPU, chargé à 76%, sont en rouge. |
La consommation de ressources par les différents processus dans la partie inférieure de l’interface : ici également l’utilisateur peut choisir quelle catégorie de ressource sera affichée (réseau, utilisateur, mémoire, ou autre). Comme pour les compteurs globaux ce choix peut se faire via des options en ligne de commandes où à partir des requêtes soumises depuis l’interface interactive. Nous y reviendrons.
02 ) QUELQUES OPTIONS UTILES.
Dans cette section, nous présenterons quelques options utiles pour un usage classique d’ATOP. Ne pouvant énumérer toutes les options, vous pouvez consulter la documentation d’ATOP pour aller plus loin.
02.1 – Sélectionner la catégorie des compteurs à afficher :
ATOP accepte différentes options de ligne de commandes avec, pour chacune, une commande équivalente que l’on peut soumettre depuis l’interface interactive ncurses.
Ces options permettent de sélectionner la catégorie des ressources que l’on souhaite superviser. Par défaut, les compteurs fournissent des informations générales sur l’utilisation du CPU par les processus. Nous listons ci-après quelques autres options d’affichage.
| 1 ► Mémoire : pour activer l’affichage des compteurs suivant la consommation mémoire, il suffit de lancer la commande atop avec l’option -m, ou alors, après le lancement de l’interface graphique, appuyer sur la touche .
~# atop –m
2 ► Disque : l’affichage des compteurs suivant l’utilisation disque se fait avec l’option -d, ou alors depuis l’interface graphique.
3 ► Réseau : l’activation de l’affichage des compteurs réseau se fait en lançant la commande atop avec l’options -n ou depuis l’interface graphique. Sachant que Linux ne fournit pas nativement de compteurs réseau par processus, atop fournit pour cela un module noyau spécial appelé « netatop« , qui s’appuie sur « nefilter » pour collecter ses compteurs. |
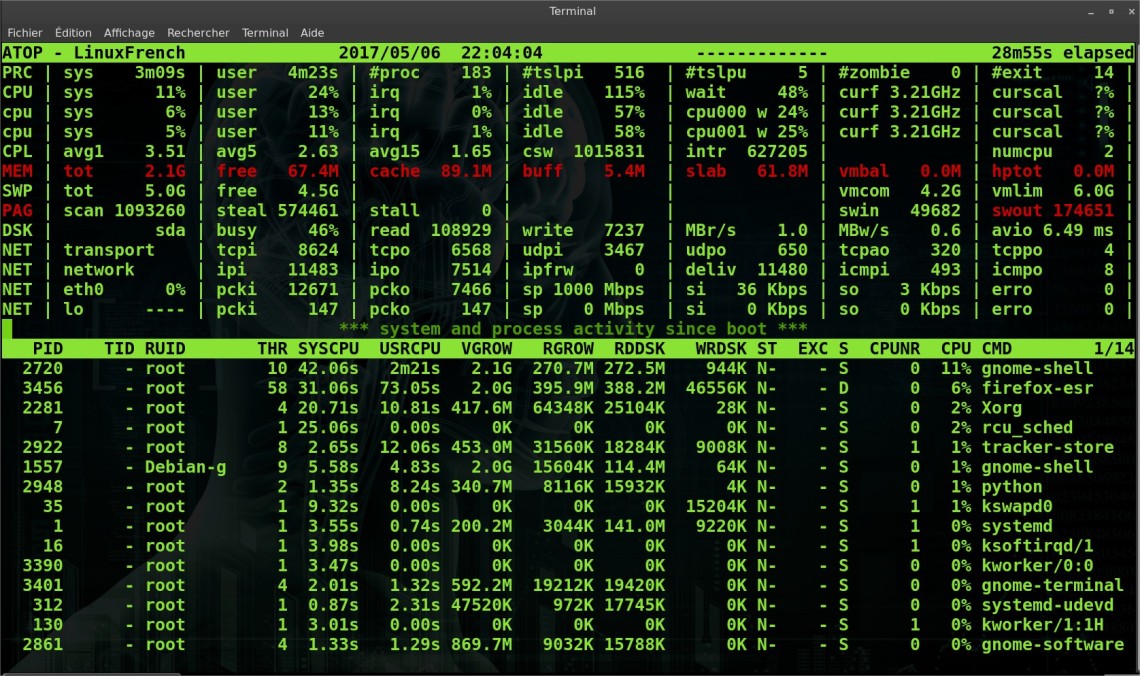
~# atop –n
02.2 – Définir l’intervalle de rafraîchissement :
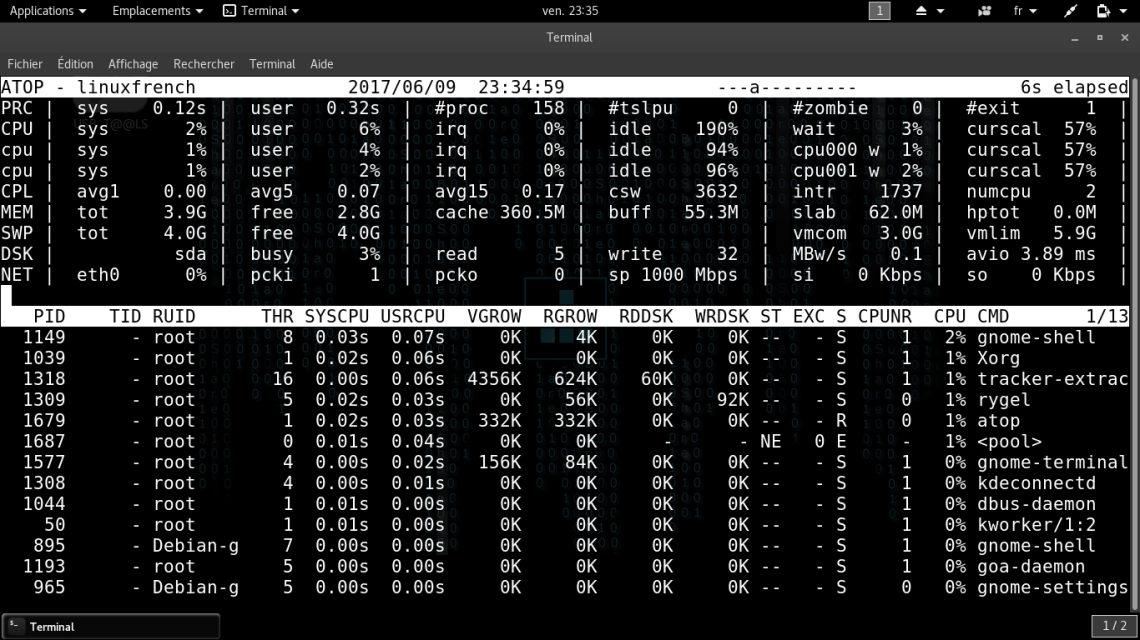
Au premier affichage, c’est-à-dire après le lancement du programme atop, les compteurs de performances affichés sont ceux calculés depuis le démarrage de la machine. Ensuite les compteurs sont rafraîchis pour ne prendre en compte que les changements ayant eu lieu depuis le dernier rafraîchissement.
La durée de rafraîchissement par défaut est de 10 secondes, mais peut être changée de deux manières :
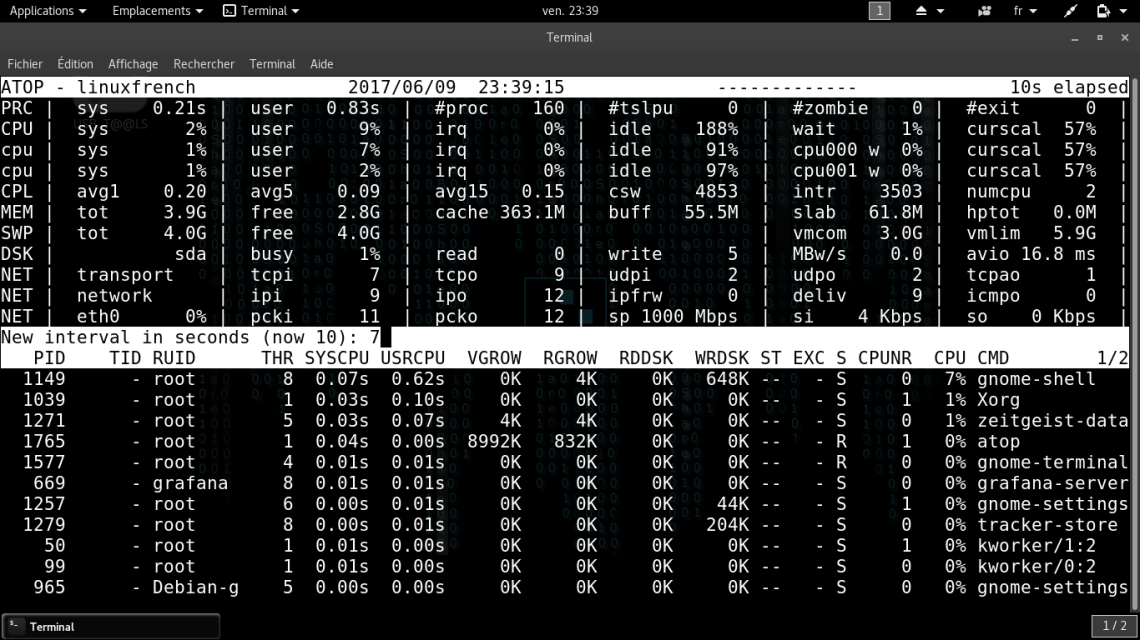
| ► Au lancement d’atop, en spécifiant la durée de l’intervalle en secondes. Par exemple, la commande suivante lancera le programme avec la durée de rafraîchissement de 5 secondes :
~$ atop 5 ► Via l’interface ncurses comme suit : appuyer sur la touche , saisissez la valeur souhaitée en secondes, et appuyer sur la touche <Entrée> pour valider et prendre en compte le changement immédiatement.
|
02.3 – Enregistrer les compteurs d’atop pour une analyse ultérieure :
Comme alternative à l’interface interactive qui nécessite que l’utilisateur soit présent devant sa console pour détecter d’éventuelles anomalies, atop permet un mode de fonctionnement où les données collectées sont automatiquement stockées dans un fichier sur le disque pour une analyse ultérieure.
02.3.1 – Collecter et stocker les données dans un fichier :
Il faut pour cela utiliser l’option -w, suivie d’un chemin de fichier. Par exemple, la commande suivante collectera et stockera les données dans un fichier nommé output.atop. Cette option peut être complété avec les autres options d’atop, conformément à la documentation.
~$ atop –w output.atop
Les données sont stockées sur une forme compressée afin de réduire l’empreinte disque.
Atop fournit par défaut un service démon, atopd, qui se base sur cette fonctionnalité pour collecter des données en arrière-plan. Ce démon permet de plus de gérer la rotation automatique des fichiers générés. Cette rotation vise à éviter d’avoir des échantillons très volumineux et donc l’analyse prendrait beaucoup de temps à cause de la décompression et du chargement en mémoire.
Grâce aux données stockées sur disque, l’administrateur système peut, en cas d’anomalie constatée sur un système, faire une analyse a posteriori pour étudier la cause de l’anomalie. En rappelant qu’atop garde les données concernant à la fois les processus actifs, inactifs, et même morts, ceci permet de faire des analyses post-mortem. C’est-à-dire des analyses qui prennent en compte des processus ayant cessé de fonctionner. L’analyse d’une anomalie par l’administrateur système peut donc facilement prendre en compte des processus qui se sont déjà terminé, normalement ou anormalement (exemple : crash, interruption utilisateur).
~# atop –P NET,MEM,CPU,cpu 2



02.3.2 – Visualiser les données depuis un fichier :
Avec des données collectées dans un fichier, atop fournit l’option -r qui permet de spécifier un fichier d’entrée à partir duquel les données vont être lues. Comme illustré sur l’exemple suivant, cette option attend en argument le chemin vers un fichier généré par atop. Si le fichier n’est pas reconnu comme un fichier atop, la commande échouera.
~$ atop –r output.atop
Pour permettre une analyse fine de ces données stockées, atop offre une option pour spécifier l’intervalle de temps concerné par l’analyse. Il faut pour cela utiliser l’option -b (date de début) et, facultativement, l’option -e (heure de fin), suivies respectivement d’une heure suivant le format hh:mm. L’exemple suivant indique que les données à analyser doivent être comprises entre 04:00 et 04:30 inclus.
~$ atop –r output.atop –b 04:00 –e 04:30
02.4 – Extraire les compteurs d’atop sous forme formatée :
L’option -p de la commande atop permet d’afficher le sortie sous forme tabulaire. Les compteurs sont alors affichés ligne par ligne avec les champs séparés par des espaces. L’objectif est de faciliter le traitement des compteurs via des outils tiers de post-traitement.
Cette option doit être accompagnée d’un ou plusieurs filtres permettant de spécifier la ou les catégories de ressources à considérer (CPU, mémoire, disque, réseau, ect.). Nous verrons un exemple d’utilisations ci-dessous. Notons en particulier que le filtre ALL (ex : atop –P ALL) permet de sélectionner l’ensemble des ressources. La liste complète des filtres peut être consultée via la page de manuel d’atop.
02.4.1 – Cas d’utilisation :
La commande suivante permet d’extraire toutes les cinq secondes les compteurs liés à tous les CPU, à la mémoire, au réseau et produit une sortie formatée comme sur l’image ci-dessous. Remarquons la différence entre CPU et cpu, en majuscule et en minuscule. Avec cpu en minuscule, il s’agit de récupérer les compteurs pour chaque cœur CPU disponible sur le système, tandis que dans le second cas où CPU est en majuscule, il s’agit des compteurs globaux issus de l’agrégation des compteurs des différents cœurs disponibles.
~# atop –P NET,MEM,CPU,cpu 2
02.4.2 – Interprétation des entrées :
Les entrées générées par l’option –P s’interprètent comme suit :
| ► Le marqueur RESET, qui apparaît une seule fois à la première ligne sur la ligne entière, indique que les compteurs qui vont suivre ont été collectés depuis le dernier démarrage du système.
► Les marqueurs SET, apparaissant également sur une ligne entière, délimitent les données collectées durant chaque intervalle de mise à jour. ► Les compteurs collectés pendant chaque intervalle de temps apparaissent entre deux marqueurs SET, ou entre le marqueur RESET et le premier marquer SET. ► Chaque ligne, hormis les lignes avec un marqueur RESET ou SET, contient différents compteurs pour une catégorie de ressource donnée. Chaque ligne commence invariablement par les six champs suivants : une étiquette indiquant la catégorie de ressource concernée (CPU, MEM, NET …), le nom d’hôte de la machine (ex : localhost), la date et l’instant d’échantillonnage en seconde depuis l’epoch (01/01/1970), la date d’échantillonnage sous le format YYY/MM/DD, l’heure d’échantillonnage sous la forme HH:MM:SS, et enfin la durée de l’intervalle d’échantillonnage (2 secondes dans l’exemple précédent). Les champs suivants varient selon la catégorie de la ressource concernée. |
Pour une interface réseau par exemple, les champs suivants seront : le nom de l’interface, le nombre de paquets reçus, le nombre d’octets reçus, le nombre de paquets transmis, le nombre d’octets transmis, le débit, et le mode de transmission (0=half-duplex, 1=full-duplex). À préciser qu’une ligne réseau avec la valeur upper au niveau du nom ne correspond pas à une interface réseau, mais aux données enregistrées au niveau des couches supérieurs de la pile TCP/IP. Les champs indiquent respectivement le nombre de paquets transmis en UDP, le nombre de paquets reçus par IP, le nombre de paquets reçus en UDP, le nombre de paquets transmis en UDP, le nombre de paquets reçus par IP, et le nombre de paquets retransmis par IP. Bien vouloir se référer au manuel d’atop pour une description exhaustive des différentes entrées selon la catégorie de ressource.
On peut constater à partir de ce cas d’utilisation que les compteurs et le niveau de détails fournis par atop sont assez fins. En revanche, les compteurs bruts ainsi produits ne sonbt pas toujours facilement interprétables pour tirer des conclusions. Pour le cas du réseau, nous aurions, par exemple, espéré avoir des débits en bits par seconde, au lieu des quantités d’octets échangés durant un intervalle de temps donné. Mais, rassurons-nous, ces informations de haut niveau que nous manipulons au quotidien peuvent être déduites par agrégation des compteurs bruts. C’est ce que nous allons voir sur le plan théorique.
03 ) VISUALISER LES DONNÉES D’ATOP AVEC GRAFANA.
Nous allons voir comment les compteurs retournés par atop peuvent être agrégés pour avoir des indicateurs de performance de haut-niveau qui seront injectés dans le moteur de visualisation de Grafana afin de simplifier leur exploitation. Nous supposons que le lecteur est familier et dispose déjà d’une installation fonctionnelle de Grafana avec Graphite (ce qui n’est pas mon cas. Désolé) comme source de données. Si ce n’est pas le cas (comme moi), vous pouvez vous inspirer de la documentation disponible ici et là.
(ça donne envie, n’est-ce pas ?)
03.1 – Agréger les compteurs sous forme de métriques Graphite :
La démarche repose sur deux scripts écris par l’équipe GNU/Linux Magasine (que je remercie au passage encore une fois) et téléchargeables sur Github : collect_atop_counters.sh et push_graphite_formatted_data_live.py. En s’appuyant sur ces scripts, la suite de commandes suivante permet d’extraire d’atop des compteurs, concernant le réseau, la mémoire et les CPU (atop –P NET,MEM,CPU,cpu), de les agréger sous forme d’indicateurs de performance de haut niveau, puis de les injecter sous forme de métriques dans une base de données Graphite. Ces indicateurs de performances peuvent ainsi être visualisés grâce à Grafana avec la commande suivante :
~$ atop –P NET,MEM,CPU,cpu | \
collect_atop_counters.sh | \
push_graphite_formatted_data_live.py
Dans un premier temps, les compteurs d’atop sont extraits via la commande atop –P NET,MEM,CPU,cpu. Ce qui produit en sortie des entrées similaires à celles présentées plus haut.
Le résultat est redirigé, via un mécanisme de pipe, au script collect_atop_counters.sh qui fonctionne comme suit : les différents compteurs issu d’atop sont agrégés pour produire des indicateurs de haut niveau, incluant entres autres, le débit réseau en bit par seconde, le nombre de paquets émis et reçus chaque seconde, le pourcentage d’utilisation de la mémoire, le niveau de charge global et individuel des CPU, ect. Cela génère en sortie les métriques. Graphite associés aux indicateurs calculés.
Chaque ligne correspond à une métrique sous la forme « clé valeur timestamp« . Les clés exploitent la capacité de gestion de structure arborescence par Graphite. Chacune suit sur la nomenclature : userPrefix.timeseries.hostname.resourceType.resourceId.metricKey, où : userPrefix est un préfixe défini librement par l’utilisateur (graphite dans l’exemple) ; timeseries est une valeur constante ; hostname est le nom d’hôte de la machine tel que retourné par atop ; resourceType est une variable déterminée dynamiquement en fonction du type de ressource (CPU, MEM,NET), resourceId correspond à l’identifiant de la ressource tel que que retourné par atop (ex : eth0 pour une interface réseau) ; metricKey correspondau nom associé à l’indicateur de performance généré (ex : recvthroughput, pour le débit de réception réseau).
Ces métriques sont ensuite reprises par un second script, push_graphite_formatted_data_live.py, grâce au mécanisme de pipe également, qui se charge de les injecter dans une base de données Graphite à travers le démon carbon cache. Les métriques sont injectées par lot en utilisant le protocole pickle. Ce qui vise à limiter les risques de saturation du démon et du réseau avec des petites requêtes. Le script nécessite deux variables d’environnement (CARBON_CACHE_SERVER et CARBON_CACHE_PICKLE_PORT), indiquant respectivement l’adresse réseau et le port d’écoute du démon carbon. Par défaut, ces variables sont définies pour se connecter sur la machine locale et le port 2004 (port par défaut du protocole pickle).
03.2 – Construire, explorer et partager des tableaux de bord Grafana :
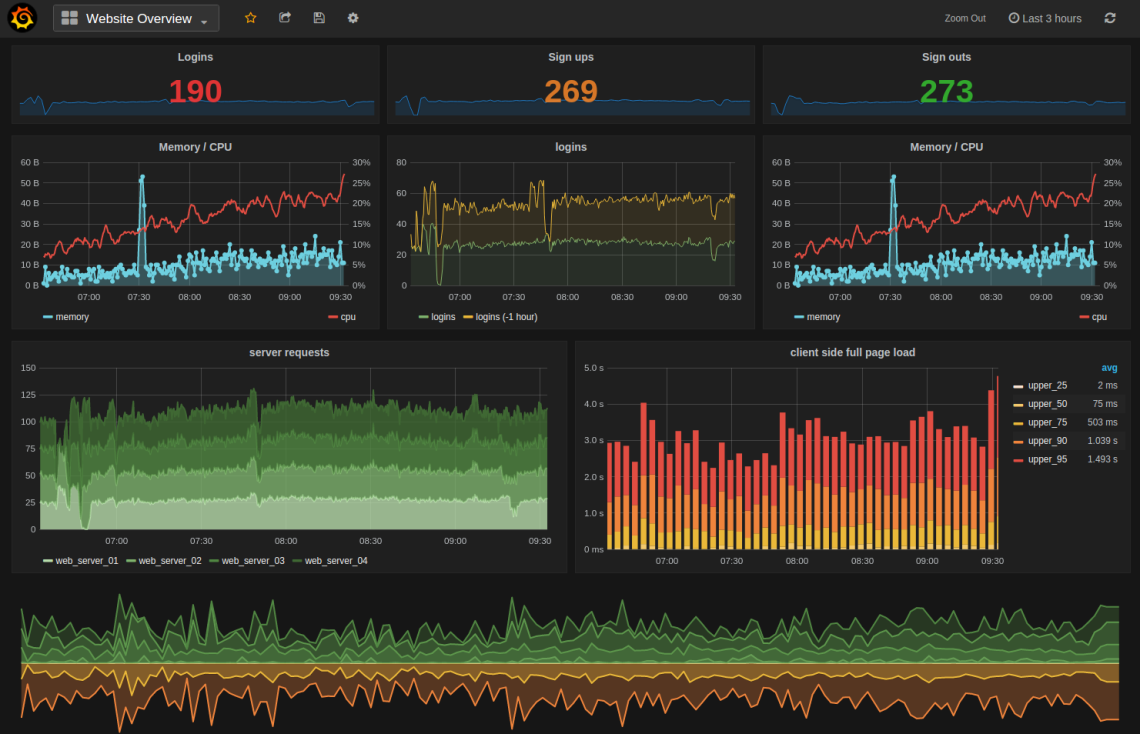
Les tableaux de bord générés à l’aide des scripts comprend quatre panneaux montrant des graphes liés : au pourcentage d’utilisation globale et par cœur des CPU, niveau d’utilisation de la mémoire, débit d’envoi et de réception pour chaque interface réseau, nombre de paquets émis et reçus via chaque interface réseau.
Grâce à ce type de tableau de bord, nous voyons comment nous pouvons superviser en temps réel, depuis des écrans dans une salle de supervision par exemple, les performances de nos serveurs. Depuis la version 3.1.0, il est possible de partager des tableaux de bord sur le site de Grafana.net. En exploitant cette fonctionnalité, vous pourrez partager des tableaux de bord que vous pourrez ensuite télécharger (modèles) pour les utiliser conjointement avec les scripts fournis précédemment.
CONCLUSION :
Nous avons vu dans cet article l’outil atop, qui est un outil en ligne de commandes interactif pour la supervision de performance sur des systèmes basés sur Linux. Puissant et pointu au niveau détail, il souffre cependant d’une interface impraticable dans un contexte opérationnel où une visualisation rapide est capitale. C’est pour cela que nous avons montré comment grâce à quelques astuces et scripts, les compteurs d’atop pouvaient être aisément extraits, agrégés, et injectés dans un moteur de visualisation basé sur Graphite et Grafana afin de créer des tableaux de bord flexibles pour une supervision opérationnelle. Atop est un outil riche, et nous ne pouvions aborder toutes ses fonctionnalités dans un seul article. Nous invitons donc les lecteurs à consulter la page de manuel pour en apprendre d’avantage. Le dépôt Github des scripts d’exemple fournis reste ouvert aux contributions.
![]()
(Merci beaucoup à l’auteur de cet article , Tristan Colombo , son projet, et à l’équipe GNU/Linux Magasine]

Bonjour,
Je suis auteur original de cet article.
N’ayant pas souvenir d’avoir céder les droits de paternalité pour ne pas être mentionné tel quel comme auteur, j’ai du mal à imaginer que vous ayez reçu l’accord de Linux Magazine pour cette publication.
Ceci me semble être du plagiat.
Pouvez-vous vous mettre en règle, au risque de poursuites conformément à la loi.
R.
J’aimeJ’aime
Désolé, je pensais que la philosophie de Linux était le partage. Tout « mes » articles sont tirées de divers magasines et autres. Maintenant c’est vrai qu’au début, je citais seulement le magasine et non l’auteur. Chose que j’ai rectifié mais pas mi à jour sur les anciens articles. Veuillez m’excuser de partager… Maintenant dites moi soit votre nom pour que je le cite ou alors j’efface cet article et ainsi je prive toutes ses personnes qui non pas 12e à mettre ? Tout ça pour « un nom ». Je peux comprendre mais de cette manière, j’ai un peu de mal. Heureusement que vous êtes pas un « représentant de Linux » car j’aurai pu être déçu et me faire oublier ce projet que j’ai de faire basculer un maximum de personnes sur Linux et de leurs faire « oublier » un peu Windows…Si pas de réponse, l’article sera supprimé ce midi.
Cordialement.
J’aimeJ’aime
Bonjour,
Je suis le rédacteur en chef de GNU/Linux Magazine, l’un des magazines dans lesquels les articles que vous publiez sur ce site ont d’abord été publié.
Je pense que vous vous méprenez sur la notion de liberté de partage des articles tirés de différents magazines, pas seulement d’ailleurs des magazines issus des éditions Diamond (Linux Magazine, Linux Pratique, MISC et Hackable). Reprenez les articles de Richard Stallman : libre ne signifie pas gratuit. Il y a une loi sur les droits d’auteur à respecter et nous n’avons pas libéré cet article (ce qui est le cas de certains de nos articles… mais pas celui-ci) en Creative Common by-NC-ND (https://creativecommons.org/licenses/by-nc-nd/2.0/fr/legalcode). Si cela avait été le cas, vous auriez pu effectivement le distribuer en citant l’auteur, la licence et la référence de la parution.
Je ne doute pas un instant que vous pensiez bien faire mais vous êtes dans l’illégalité la plus totale. D’autre part, je ne saurais que trop vous conseiller d’ajouter des mentions légales à votre site, mention qui sont obligatoires et bien entendu de supprimer l’ensemble des articles issus de nos publications et qui ne sont pas en Creative Commons.
Cordialement,
TC
J’aimeJ’aime
Bonjour,
effectivement, je pensais qu’à partir du moment que j’achetais le magasine, je pouvais partager son contenu. Après il est vrai que mon erreur (qui a été rectifiée depuis) était de ne pas citer le nom de l’auteur mais juste la provenance du sujet (le magasine). Je vous avouerai que je suis très déçut de la part des ses auteurs car peux de mes lecteurs sont capable de mettre 12 euros pour un magasine. Je suis pas informaticiens, c’est juste une passion et la joie de partager. Et comme je travail, je peux me permettre d’acheter vos magasines contrairement à d’aures et ensuite je partage ce qui me semble intéressant.
Après il faut que vous preniez en compte que vos magasines ne paraissent pas partout (en Belgique par exemple, il n’y a pas de magasine sur Linux) et que plus de 75% des lecteurs n’habite pas en France.
Puis oui, ma déception est bien plus grande quand je me remémore la façon dont j’ai connu Linux (des personnes distribué la distribution OpenSuse gratuitment à la braderie de Lille. J’ai discuté avec ses personnes et leur philosophie à propos de l’Open Source, tout ça, m’a de suite convaincu et retiré Windows. Apparemment ce n’est pas celle de ses auteurs . Enfin…Désolé. )
Je vais donc recherché après mes magasines et si pour la fin de semaine je les aient pas retrouvé (car je prête aussi…), j’effacerais l’ensemble des articles (voir le blog et la page Facebook) et je me renseignerai comme il faut avant de perdre mon temps du coup à tout retaper à la main.)
Les auteurs concerné vont décevoir beaucoup de personnes (j’arrive pas à les comprendre. Je partage beaucoup d’Art visuelle aussi et généralement, les personnes sont très heureuses de voir leurs travaux partagés.Je voyais le monde de l’Open Source comme une forme d’Art…)
Pourtant vos auteurs doivent bien connaître comment Linux a été bâti ? (il ne s’agit pas d’un sujet dans un magasine là mais d’un code source qui constitue le noyau de Linux que Mr Torvalds a partagé sous un pseudo.). Et le protocole FTP, ça leurs parlent aussi ?
Enfin pardonnez-moi mais je suis…Abasourdi. Oui, abasourdi et très déçu d’une telle réaction. Quand je lisais le magasine, je pensais lire des personnes avec la même vision que moi et ses personnes que j’avais rencontré.
Ce weekend tout sera rétabli.
Cordialement, Olivier.
PS : Désolé pour les fautes d’orthographe. Peu diplômé et debout depuis 3h ce matin.
J’aimeJ’aime
Bonjour,
effectivement, je pensais qu’à partir du moment que j’achetai le magasine, je pouvais partager son contenu. Après il est vrai que mon erreur (qui a été rectifiée depuis) était de ne pas citer le nom de l’auteur mais juste la provenance du sujet (le magasine). Je vous avouerai que je suis très déçut de la part des ses auteurs car peux de mes lecteurs sont capable de mettre 12 euros pour un magasine. Je suis pas informaticiens, c’est juste une passion et la joie de partager. Et comme je travail, je peux me permettre d’acheter vos magasines contrairement à d’autres et ensuite je partage ce qui me semble intéressant.
Après il faut que vous preniez en compte que vos magasines ne paraissent pas partout (en Belgique par exemple, il n’y a pas de magasine sur Linux) et que plus de 75% des leteurs n’habite pas en France.
Puis oui, ma déception est bien plus grande quand je me remémore la façon dont j’ai connu Linux (des personnes distribué la distribution OpenSuse gratuitement à la braderie de Lille. J’ai discuté avec ses personnes et leur philosophie à propos de l’Open Source, tout ça, m’a de suite convaincu et retiré Windows. Apparemment ce n’est pas celle de ses auteurs . Enfin…Désolé. )
Je vais donc recherché après mes magasines et si pour la fin de semaine je les aient pas retrouvé (car je prête aussi…), j’effacerais l’ensemble des articles (voir le blog et la page Facebook) et je me renseignerai comme il faut avant de perdre mon temps du coup à tout retaper à la main.)
Les auteurs concerné vont décevoir beaucoup de personnes (j’arrive pas à les comprendre. Je partage beaucoup d’Art visuelle aussi et généralement, les personnes sont très heureuses de voir leurs travaux partagés.Je voyais le monde de l’Open Source comme une forme d’Art…)
Pourtant vos auteurs doivent bien connaître comment Linux a été bâti ? (il ne s’agit pas d’un sujet dans un magasine là mais d’un code source qui constitue le noyau de Linux que Mr Torvalds a partagé sous un pseudo.). Et le protocole FTP, ça leurs parlent aussi ?
Enfin pardonnez-moi mais je suis…Abasourdi. Oui, abasourdi et très déçu d’une telle réaction. Quand je lisais le magasine, je pensais lire des personnes avec la même vision que moi et ses personnes que j’avais rencontré.
Ce weekend tout sera rétabli.
Cordialement, Olivier.
PS : désolé pour les fautes d’orthographes. Peu diplômé et debout depuis 3h ce matin.
J’aimeJ’aime
Merci de bien vouloir donc mentionner l’auteur et un lien vers la page du projet : https://github.com/rchakode/atop-graphite-grafana-monitoring
J’aimeJ’aime
Nous vous prions de retirer tout le contenu dont la diffusion n’a pas été autorisée explicitement par nos soins.
Bien que nous comprenions votre intention initiale, nous vous invitons à vous renseigner d’avantage sur la notion de droit d’auteur en France.
« Free software is a matter of liberty, not price. To understand the concept, you should think of free as in free speech, not as in free beer. » — Richard Stallman
TC
J’aimeJ’aime
Bonjour,
En tant que auteur original de cet article, je reviens vers vous car depuis les derniers commentaires, vous avez fait des modifications mais non conformes à la demande initiale.
D’une part, renseignez-vous bien sur la notion de droit d’auteur, ainsi que sur les licences libres. Vous faites beaucoup d’amalgames…
D’autre part, vos modifications sont erronées. Car notez que :
– GNU Linux Magazine, via Éditions Diamond, n’est pas auteur de cet article (l’auteur original de chaque article est noté au début de ce dernier dans le magazine, votre «saisie» est incomplète…)
– Les scripts et le projet associés à l’article ne sont pas, eux non plus, la propriété de Linux Magazine, mais de l’auteur que vous pouvez simplement trouver sur Github.
Je vous prierais de bien vouloir prendre en compte ces commentaires, notez que vous vous exposez et votre site à des sanctions pouvant aller à la fermeture du site en cas de plaintes que je m’apprête à déposer auprès des instances compétentes (Belgique incluses).
R.
J’aimeJ’aime